
AI Improves Pediatric, Ophthalmologic, and Dermatologic Monitoring
March 1, 2024
2021 – 2022
March 1, 2024AI Technology Semi-Supervised Machine Learning


Usually, learning has been studied in both the unsupervised pattern, where all the data are unlabeled, and the supervised pattern, where all the data are labeled. Semi-supervised learning aims to comprehend how a combination of labeled and unlabeled data may transform the learning behavior and design systems that benefit from such a pattern.(1)
Semi-supervised learning is of unlimited interest in machine learning because it can use willingly accessible unlabeled data to expand supervised learning jobs when the labeled data are infrequent or high-priced .(1)
Usually, learning has been studied in both the unsupervised pattern, where all the data are unlabeled, and the supervised pattern, where all the data are labeled. Semi-supervised learning aims to comprehend how a combination of labeled and unlabeled data may transform the learning behavior and design systems that benefit from such a pattern.(1)
Semi-supervised learning is of unlimited interest in machine learning because it can use willingly accessible unlabeled data to expand supervised learning jobs when the labeled data are infrequent or high-priced.(1)
Semi-supervised learning permits the algorithm to learn from a small volume of labeled manuscripts while still organizing large amounts of unlabeled manuscripts in the training data.
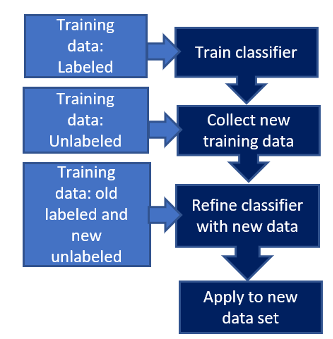
Semi-supervised learning approaches use unlabeled and labeled data to create a model, as illustrated in Figure 1. Labeled data are nominated by the researcher and depend on the research query and study project. This labeled data is expended to mature a model for foreseeing the result (dependent variable).
After the model is created, an iterative course is originated in which the model is used to an unlabeled data set. The newly labeled data are formally added to the labeled data set, and the machine learning process is run to mature an updated model. This iterative course introduces models with an enhanced fit as supplementary data is added.(2)
This model can iteratively operate this data as data are labeled immediately and predict the results responsive to in-the-moment proceedings. Compared to unsupervised machine learning methods, semi-supervised methods should expand a model’s performance, analytical skills, and generalizability by embracing labeled data .(2)
Semi-supervised learning permits the algorithm to learn from a small volume of labeled manuscripts while still organizing large amounts of unlabeled manuscripts in the training data.
Semi-supervised learning approaches use unlabeled and labeled data to create a model, as illustrated in Figure 1. Labeled data are nominated by the researcher and depend on the research query and study project. This labeled data is expended to mature a model for foreseeing the result (dependent variable).(2)
After the model is created, an iterative course is originated in which the model is used to an unlabeled data set. The newly labeled data are formally added to the labeled data set, and the machine learning process is run to mature an updated model. This iterative course introduces models with an enhanced fit as supplementary data is added .
This model can iteratively operate this data as data are labeled immediately and predict the results responsive to in-the-moment proceedings. Compared to unsupervised machine learning methods, semi-supervised methods should expand a model’s performance, analytical skills, and generalizability by embracing labeled data . (2)
In order to make it conceivable for semi-supervised learning methods to create the majority of the labeled and unlabeled data, some assumptions are made for the fundamental structure of data. The theories, smoothness, and cluster assumptions are the foundation for every one of the state-of-the-art techniques.
In the smoothness assumption, it is expected that points situated close to each other in the data space are more likely to assign the same label. In the cluster assumption, it is expected that the data points that fit into one class are more likely to create and share a set/cluster of points. Consequently, the core objective of these two assumptions is to confirm that the discovered decision borderline lies in low-density rather than high-density areas within data space.
The most significant fundamental and simplest SSL method is self-training, which includes frequently training and retraining a statistical model. Primary labeled data is used to train an original model, and then this model is used for the unlabeled data. The unlabeled points for which the model is most self-assured in transfer labels are then added to the pool of labeled points, and a new model is trained. This course is repeated until some junction is usually met .(3)
Semi-supervised learning methods try to achieve unlabeled data to improve learning functioning, especially when there are narrowly labeled training examples.Because semi-supervised learning necessitates less human effort and gives higher precision, it is of significant consideration in theory and practice .(4)